

- Categoria
- Lingua
- Data di pubblicazione
Ambienti di test effimeri per flussi di CI
Come usare i vCluster e Argo Workflow per gestire ambienti di test effimeri
Perchè mai dovremmo avere questa esigenza?
A partire dai primmi anni 2000 iniziò ad essere evidente che le applicazioni monolitiche necessitavano di essere più scalabili per evitare di bloccare la crescita del business e la sua scalabilità. Dopo qualche anno, nel 2011, durante un workshop di software architect organizzato vicino a Venezia, un nuovo modello architetturale dei software stava compiendo i primi passi: i microservizi. Il modello a microservizi è in grado di scalare per soddisfare quei requisiti di business che richiedono l’esecuzione di più istanze dello stesso servizio su diversi server. In questo scenario diversi team di sviluppo lavorano su diversi microservizi aumentando la produttività e la competenza sul codice prodotto, cosa che con le applicazioni monolitiche era difficile da ottenere. Di conseguenza, fu sempre più evidente come il modello a microservizi permettesse questa scalabilità delle applicazioni e dei team di lavoro.
Molti lettori ormai avranno già pensato: ok, ma non è tutto oro quello che luccica! Siamo sicuri che l’adozione di questo approccio non porti con se anche degli effetti collaterali? Cosa succede se proviamo ad adottare questo modello nell’ecosistema cloud-native usando degli ambienti basati su Kubernetes?
Chiunque abbia già valutato o vissuto in prima persona questo percorso di dozione può testimoniare come si presenti in maniera concreta il rischio di assemblare un mostro chiamato dependecy hell.
Dependency hell is a colloquial term for the frustration of some software users who have installed software packages which have dependencies on specific versions of other software packages. The dependency issue arises when several packages have dependencies on the same shared packages or libraries, but they depend on different and incompatible versions of the shared packages. If the shared package or library can only be installed in a single version, the user may need to address the problem by obtaining newer or older versions of the dependent packages. This, in turn, may break other dependencies and push the problem to another set of packages.
Durante il ciclo di rilascio di ogni pacchetto software uno degli obiettivi più importanti di ogni gruppo di sviluppo è quello di poter implementare e testare il codice prodotto essendo sicuri di utilizzare la versione corretta di ogni dipendenza, come altri microservizi o database.
Come si può ottenere un ambiente temporaneo su richiesta dove poter effettuare tutti i miei test in sicurezza?
Quindi? Qual’è il problema?
Questo tipo di richiesta si presenta molto spesso e usualmente richiede più risorse infrastrutturali per poter replicare tutte le dipendenze in un ambiente completamente isolato. Normalmente non è possibile preparare agevolmente un ambiente di questo tipo sul dispositivo a disposizione dello sviluppatore, e in ogni caso ogni gruppo di sviluppo non riesce a richiedere in tempi brevi un nuovo ambiente kubernetes per poter procedere con i test a causa anche dei costi legati alle risorse infrastrutturali. Allo stesso tempo si evita di eseguire questo tipo di verifiche nell’ambiente di sviluppo condiviso con gli altri gruppi per evitare che i test vengano invalidati da altri rilasci effettuati nella stessa finestra temporale.
Una possibile soluzione: vCluster + Argo Workflow
Analizzando i requisiti dello use case, una possibile soluzione è quella di sfruttare vCluster di Loft. Utilizzando questo strumento l’utente può creare un cluster Kubernetes temporaneo all’interno di uno già esistente. Il virtual cluster espone in diversi modi le API di un control plane completamente separato. I vCluster sono una valida opzione quando all’interno di un cluster Kubernetes si presenta il requisito di gestire la multi tenancy utilizzando l’infrastruttura già messa a disposizione. L’adozione e il suo utilizzo non risultano eccessivamente complessi, e non è necessario installare altre dipendenze sul cluster. Un altro aspetto interessante è che non servono particolari percorsi formativi per iniziare ad utilizzare i vCluster in quanto dopo la loro creazione viene fornito semplicemente un Kubernetes API Server endpoint standard per poter iniziare eseguire comandi tramite kubectl.
In questo esperimento mi sono divertito provando ad integrare questa tecnologia con Argo Workflow, un workflow execution engine specifico per Kubernetes. Questo engine fornisce un modo efficiente per configurare l’orchestrazione di rilasci, del loro test e della loro eventuale dismissione. Lo strumento abilita l’utente finale a disegnare ed implementare dei DAG (Directed acyclic graph), riuscendo quindi supportare anche lo sviluppo di scenari complessi dove persiste il requisito di alto parallelismo dei task eseguiti.
Questa combinazione quindi offre una soluzione veloce, conveniente e scalabile facendo risparmiare molte attività di manutenzione richieste per creare e gestire un nuovo cluster Kubernetes ogni volta che questo sia richiesto.
Demo Project
URL: https://github.com/banshee86vr/ephemeral-test-environment
Struttura del progetto:
.
├── argo-workflow
│ └── lang
└── hello-world-appargo-workflow: cartella contenente i template delle pipeline di CI/CDlang: cartella contenente i diversi ArgoWorkflow Templates per i linguaggi di programmazione supportatihello-world-app: Applicazione Hello World implementata in Go che effettua una print di fantastico un 🐙 in ASCII code
Requisiti
- Minikube
kubectlcommand-line installata e configurata per connettersi al cluster Kubernetes esistente- Helm versione
3.xinstallato
Step di preparazione
1. Start Minikube e installazione Argo Workflows usando Helm
minikube start
helm repo add argo https://argoproj.github.io/argo-helm
helm install argo-workflows argo/argo-workflows -n argo --create-namespaceQuesto comando installa Argo Workflows nel namespace argo sul cluster Kubernetes.
2. Verifica dell’installazione
Per verificare che l’installazione sia avvenuta con successo eseguire:
kubectl get pods -n argoNella lista risultante dei pod in stato Running dovrebbero esserci dei pod con prefisso workflow-controller e argo-server.
3. Patch della configurazione di autenticazione per argo-server
Come riportato dalla documentazione ufficiale: https://argo-workflows.readthedocs.io/en/latest/quick-start/#patch-argo-server-authentication
The argo-server (and thus the UI) defaults to client authentication, which requires clients to provide their Kubernetes bearer token to authenticate. For more information, refer to the Argo Server Auth Mode documentation. We will switch the authentication mode to
serverso that we can bypass the UI login for now:
kubectl patch deployment \
argo-server \
--namespace argo \
--type='json' \
-p='[{"op": "replace", "path": "/spec/template/spec/containers/0/args", "value": [
"server",
"--auth-mode=server"
]}]'4. Accesso alla UI di Argo Workflows UI (Opzionale)
Argo Workflows fornisce un’interfaccia utente web per gestire e monitorare i workflows. Per accedere alla UI è necessario esporre il relativo service Kubernetes:
kubectl port-forward svc/argo-server -n argo 2746:2746A questo punto è possibile accedere tramite browser alla UI di Argo Workflows all’indirizzo http://localhost:2746.
5. Aggiungere permessi al service account di Argo
Vengono aggiunti questi livelli di permessi solamente a scopo dimostrativo. È FORTEMENTE SCONSIGLIATO REPLICARE QUESTO TIPO DI CONFIGURAZIONE IN AMBIENTI DI PRODUZIONE
Questo commando associa il clusterrole cluster-admin ai service account argo:argo-server e argo:default. In questo modo Argo Workflow potrà gestire qualsiasi tipo di risorsa in ogni namespace del cluster.
kubectl create clusterrolebinding argo-admin-server --clusterrole=cluster-admin --serviceaccount=argo:argo-server -n argo
kubectl create clusterrolebinding argo-admin-default --clusterrole=cluster-admin --serviceaccount=argo:default -n argoNegli ambienti produttivi è consigliabile creare dei ruoli dedicati in modo tale da permettere solamente l’associazione dei verbs necessari sulle risorse gestite dai workflow.
6. Preparare i secrets richiesti dalle pipeline
In caso di utilizzo di repository Git privati eseguire questo comando per permettere l’esecuzione del comando clone eseguito dalla pipeline ci.yaml:
kubectl create secret generic github-token -n argo --from-literal=token=.........Questo comando crea un secret che contiene le credenziali per eseguire il push delle immagini Docker sul registry:
export DOCKER_USERNAME=******
export DOCKER_TOKEN=******
kubectl create secret generic docker-config --from-literal="config.json={\"auths\": {\"https://ghcr.io/\": {\"auth\": \"$(echo -n $DOCKER_USERNAME:$DOCKER_TOKEN|base64)\"}}}"7. Applicare i manifest Argo WorkflowTemplate
git clone https://github.com/banshee86vr/ephemeral-test-environment.git
cd argo/workflow
kubectl apply -f ci.yaml
kubectl apply -f lang/go.yaml
kubectl apply -f cd.yamlStep esecutivi
Dopo aver completato tutti i passi preparatori ed avere installato e configurato Argo Workflow si può procedere creando ed eseguendo i workflow.
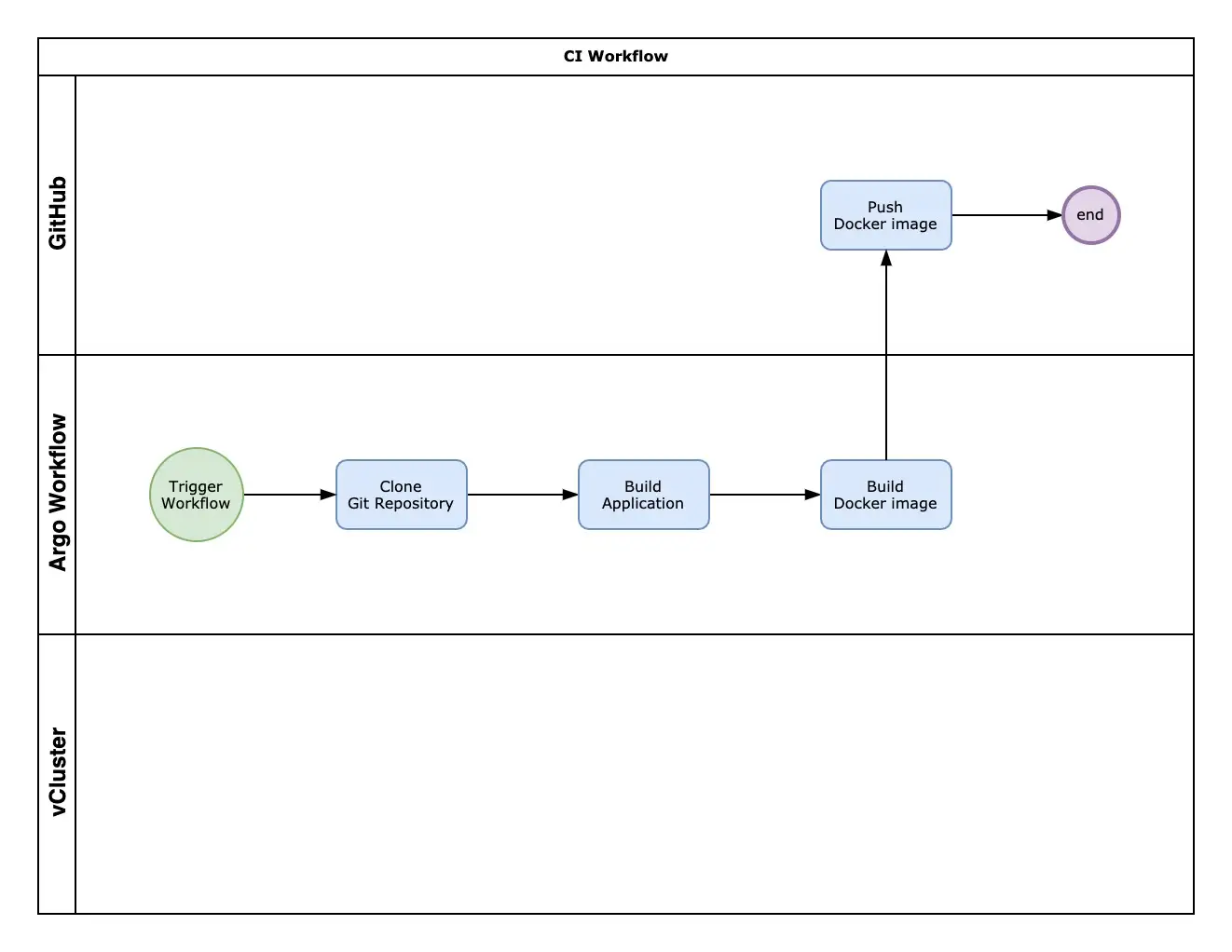
8. Submit della pipeline di Continuous Integration
La pipeline di Continuous Integration esegue gli step previsti all’interno del manifest ci.yaml:
- Clone del Repository: Prepara in locale il codice sorgente prelevato dal repository Git.
- Esegue il build dell’applicazione: Compila l’applicazione Hello World in Go utilizzando il template GoLang go.yaml.
- Build e Push dell’immagine Docker: Produce l’immagine Docker ed esegue la push sul registry.
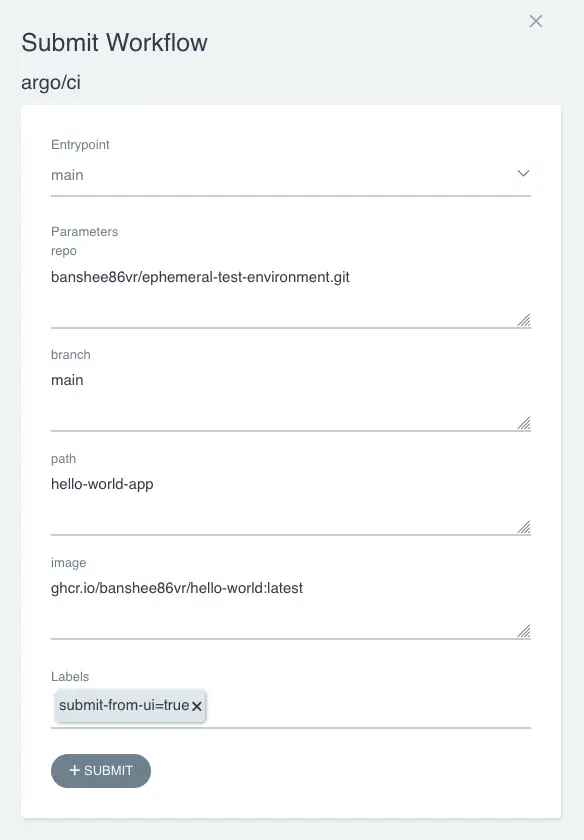
Per eseguire la pipeline di CI è possibile usare l’API ufficiale official APIs:
<ArgoWorkflow URL>/api/v1/workflows/{namespace}/submitIn alternativa è possibile utilizzare l’interfaccia utente:
Dopo il completamento di tutti gli step, controllare il corretto stato di ogni task e verificare la presenza dell’immagine Docker nel registry:

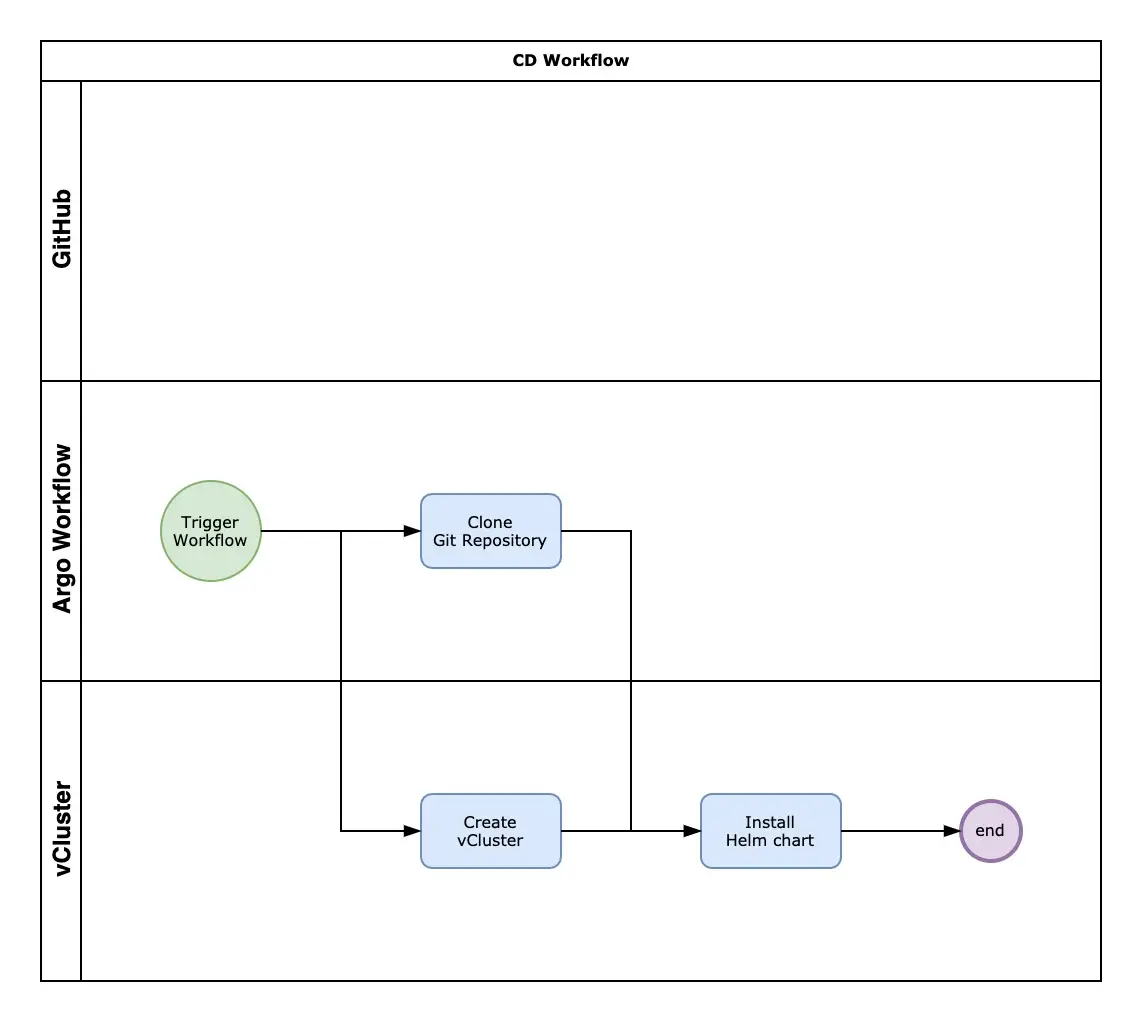
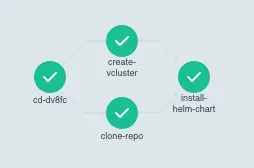
9. Submit della pipeline di Continuous Delivery
La pipeline di Continuous Delivery esegue gli step previsti nel manifest cd.yaml:
- Preparazione dell’ambiente effimero: Preparazione dell’ambiente temporaneo usando vCluster dove l’utente potrà testare la sua applicazione in un ambiente isolato.
- Deploy dell’applicazione: Deploy dell’applicazione tramite Helm chart sul vCluster appena creato.
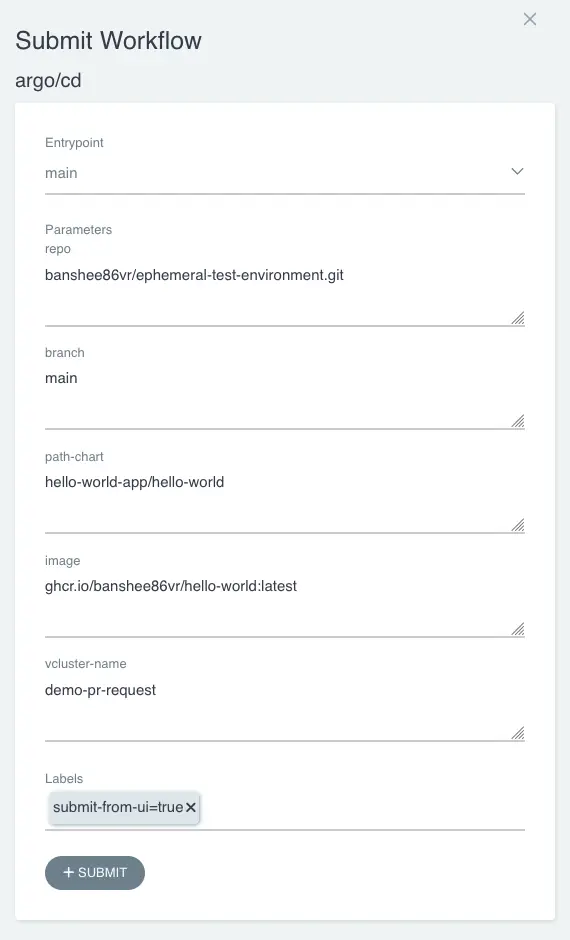
Per eseguire la pipeline di CI è possibile usare l’API ufficiale official APIs:
<ArgoWorkflow URL>/api/v1/workflows/{namespace}/submitIn alternativa è possibile utilizzare l’interfaccia utente:
Dopo il completamento di tutti gli step, controllare il corretto stato di ogni task:
10. Accesso all’applicazione
Per verificare come accedere all’applicazione è possibile esegure questi comandi per elencare tutti i vCluster ed accedere a quello interessato:
$ vcluster list
NAME | CLUSTER | NAMESPACE | STATUS | VERSION | CONNECTED | CREATED | AGE | DISTRO
------------------+----------+-----------------+---------+---------+-----------+-------------------------------+---------+---------
demo-pr-request | minikube | demo-pr-request | Running | 0.19.0 | | xxxx-xx-xx xx:xx:xx +0100 CET | 1h8m49s | OSS
$ vcluster connect demo-pr-request --namespace demo-pr-request -- kubectl get pod -n demo-pr-request
NAME READY STATUS RESTARTS AGE
demo-pr-request-hello-world-7f6d78645f-bjmjc 1/1 Running 0 7sCome riportato qui, è possibile esporre in diversi modi i vCluster:
-
Via Ingress: Un Ingress Controller con una configurazione SSL passthrough dovrebbe fornire l’esperienza utente migliore. Per fare ciò verificare che l’ingress controller sia installato e funzionante sul cluster che ospita il vCluster. Per maggiori dettagli fare riferimento qui
-
Via LoadBalancer service: Il modo più semplice, utilizzando l’opzione
--exposedurante la fase di creazione del vCluster verrà creato anche un service di tipo LoadBalancer. Il risultato dipende dalla specifica implementazione del cluster Kubernetes che ospita il vCluster. -
Via NodePort service: È possibile esporre il vCluster anche tramite un servizio NodePortYou. In questo caso è necessario creare il servizio NodePort e modificare il file
values.yamlusato per la creazione del vCluster. Per maggiori dettagli fare riferimento qui -
From Host Cluster: Per accedere al vCluster direttamente dal cluster che lo ospita è possibile connettersi direttamente al vCluster service creato. Verificare in questo caso la raggiungibilità del service e creare un kubeconfig dedicato tramite questo comando:
vcluster connect my-vcluster -n my-vcluster --server=my-vcluster.my-vcluster --insecure --update-current=false
Abbiamo veramente risolto il nostro problema?
Con il progetto demo è stato dimostrato quanto sia facile integrare un flusso di CI usando l’engine di Argo Workflow per effettuare il rilascio di un’applicazione in un ambiente temporaneo ed isolato creato tramite vCluster che contiene tutte le eventuali dipendendenze. Per questo è importante considerare che ogni vCluster può essere inizializzato e personalizzato tramite manifest .yaml o Helm charts. Tipicamente ogni microservizio può contenere già le proprie dipendenze in altri Helm charts o in manifest .yaml. Quindi con i vCluster il gruppo di sviluppo può decidere quale versione del chart utilizzare per inizializzare il vCluster per testare la relativa applicazione.
Come possiamo governare il ciclo di vita di questi vCluster effimeri?
Durante il progetto demo abbiamo visto come creare cluster dinamicamente. Ma ora dovremmo preoccuparci della loro gestione:
- Come possiamo ottimizzare le risorse utilizzare del vCluster?
- Possiamo eliminare il vCluster automaticamente?
- In quale modo posso automatizzare qualsiasi operatività manuale?
- Come posso prevenire la proliferazione di questi ambienti effimeri?
Il team di Loft ci aiuta per poter soddisfare tutti queste tematiche. La versione open source non è sufficiente a coprire nativamente tutti i requisiti, ma:
- Quotas e limits (già disponibile con la versione open source): un manifest standard Kubernetes
ResourceQuotapuò essere applicato per poter prevenire l’eccessivo utilizzo di risorse da parte del vCluster - Creazione ed eliminazione automatica: Queste operazioni possono essere scatenate utilizzando Argo Events. Questo framwork event-driven permette di agganciare eventi e workflow a webhook forniti dai tool di gestione centralizzata del codice; ad esempio, il cambio di stato di una pull request.
- Ottimizzazione delle risorse usate dai vCluster: a riguardo Lof fornisce una funzionalità di monitoraggio per gestire i periodi di inattività del vcluster ed evitare sprechi di risorse. La versione Enterprise del tool (vCluster.PRO) offre due funzionalità che ci possono tornare utili in tal senso. La prima si chiama
Sleep Modee permette di impostare il vCluster in una modalità dormiente quando non viene utilizzato, eliminando tutti i pod ma mantenendo tutte le risorse all’interno del vCluster. La seconda si chiamaAuto-deletee permette di eliminare l’intero vCluster dopo un certo periodo di inattività. Per questo, nel caso non sia possibile adottare vCluster.PRO, è possibile implementare un workaround utilizzando i CronJob l’immagine Docker contenente la CLI di vCluster per poter schedulare lo start e lo sleep/resume del vCluster seguendo il formato standard di schedulazione di cron.
Quindi cosa ci portiamo a casa?
Integrando Argo Workflows con vCluster abbiamo implementato una soluzione veloce e scalabile, permettendo ad ogni gruppo di sviluppo di poter testare la propria applicazione in maniera indipendente in un ambiente sicuro ed isolato. La possibilità di personalizzare l’inizializzazione del vCLuster permette di aggiungere qualsiasi dipendendenza necessaria, alzando il livello di qualità dei test effettuati sull’applicazione.
La stessa architettura, integrando anche Argo Events, può divenire event-driven, collegando eventi ai webhook forniti dagli strumenti di gestione centralizzata del codice, rendendola una soluzione molto conveniente in termini economici.
Tag /
